
As you would expect from an all-in-one software, the XOVI Suite also features an Onpage tool. This tool enables you to carry out onpage optimisation to improve the technical aspects of your website and make it more search-engine friendly. Onpage optimization is also about sending signals to the search engine to tell it was your website is actually about, resulting in better rankings. We know from information obtained directly from Google themselves and from the finding of SEOs that there are some simple methods to achieve better search engine results – so don’t miss out! And the good thing is, unlike with link building, you’re not dependent on the actions of third parties. Rather, onpage improvements can be carried out by yourself, particularly if you have some programming experience. Even if not, there are aspects of onpage optimization that anyone can do.
Onpage Analysis with XOVI
Having run an analysis, scroll down slightly on XOVI’s Onpage Analysis overview page to access a neatly presented list of errors, warnings and tips. Always start by looking at errors first. These are the issues which have the greatest effect on rankings. Then have a look at the warnings, followed by the tips if you have time. Users are sometimes restricted from fixing certain problems by system restrictions, for instance in shop systems. It is not always possible to carry out the necessary changes wherever they are required, so focus your attention on what’s doable. Remember, XOVI cannot identify whether improvements are possible on your system, but simply were the potential for improvement lies.
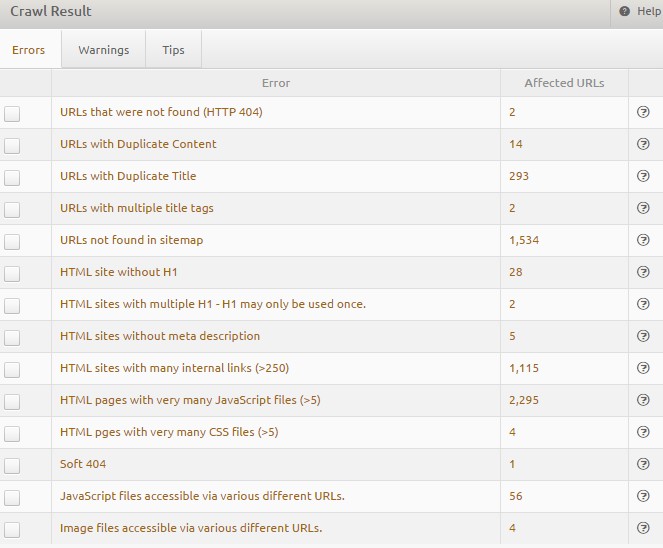
Here, we are going to present five common onpage errors and warnings from the tool and explain how to fix them. Please understand that we can only cover this rather generally since the precise changes to be made often depend on the system you are using. A content management system (CMS) such as Joomla is different from WordPress or Typo3 and shop systems like Shopware are built differently to OXID or Strato. Nevertheless, an elementary understanding of optimisation potential will lead you to the solution.
1. URLs not found (HTTP 404)
Here, the XOVI crawler has followed an internal link and has encountered a subpage which returns an HTTP 404 error. This means the page no longer exists and isn’t good either for visitors or for search engines, both of which end up at dead ends. Google evaluates this “bad user experience” as a negative, resulting in a negative effect on the ranking of your website.
For each and every inaccessible URL, XOVI shows you where exactly the link is. The easiest way to solve this problem is to adapt or delete the internal link so that visitors and crawlers aren’t led to this page.
Since pages often have external links leading to a no longer accessible page which can’t be so easily deleted (nor should they be), these should be redirected to a new URL where the relevant content can be found using a 301 redirect. If the content simply doesn’t exist anymore, we recommend a personalised 404 error page with helpful instructions and further internal links. You can even make it amusing or entertaining to counteract your visitor’s frustration.
See for example XOVI’s 404-page:
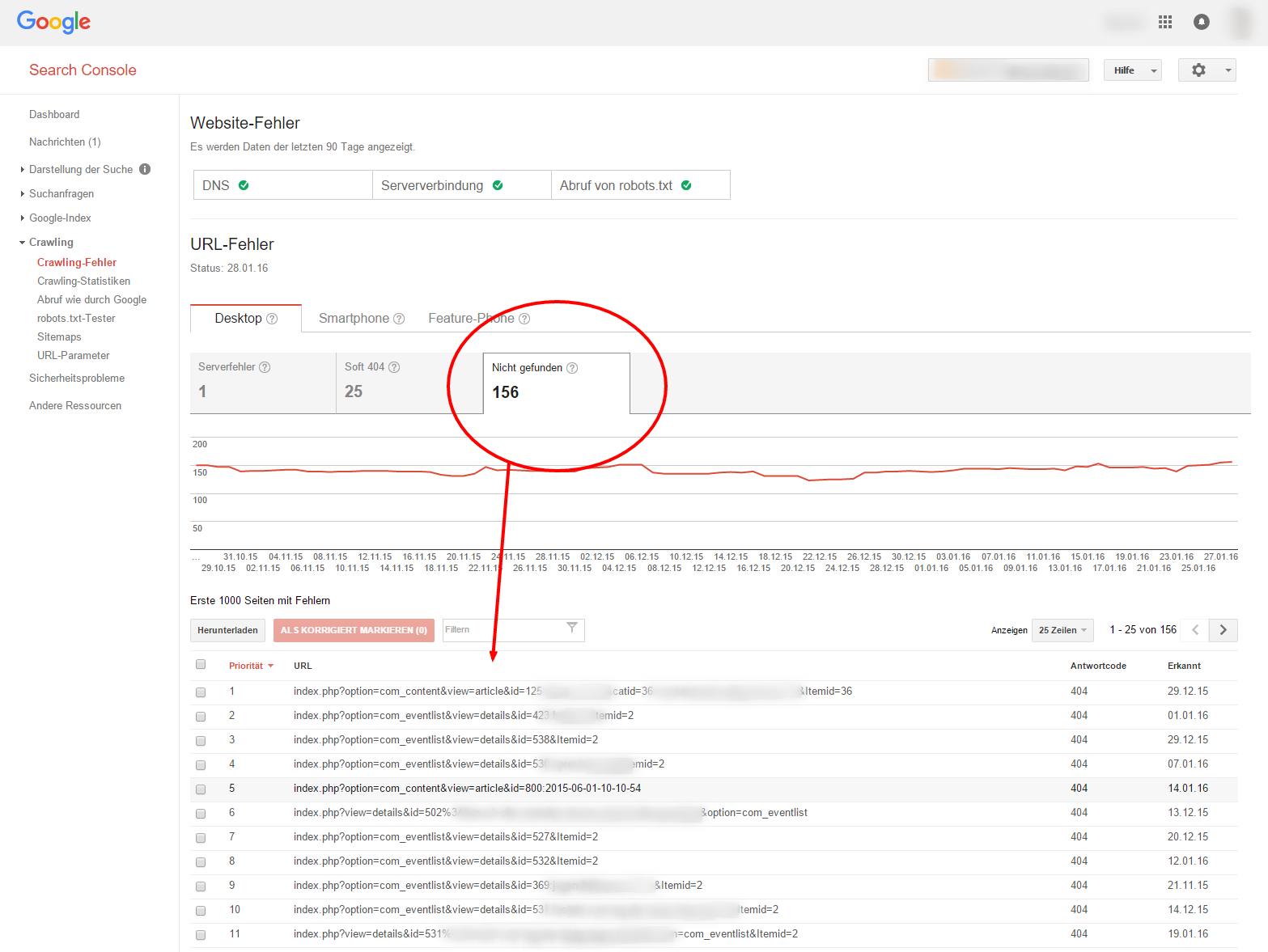
Make sure that as few pages as possible on your domain return 404 errors. One final tip: Pages which have returned 404 errors during crawling can also be found in the Google Search Console. To view these, head to “Crawling” in the main menu, followed by the sub section “Crawling errors”. Here you can see the “not found” tab, which contains crawling errors detected by Google in the previous 90 days.
2. Temporarily redirected URLs (HTTP 302/303)
302 and 303 redirects are temporary link redirects used when content is only meant to be at a different URL for a certain period of time before the redirected link becomes valid again. Strictly speaking, the implementation of a temporary redirect is not an error, but they are often used instead of permanent redirects. Why is this not ideal?
Let’s say the content of a URL on a webpage is now found under a different URL because you have permanently rearranged the link structure. The change is permanent. But by using a 302 or 303 redirect, you are signalling to the search engine that this change is only temporary. Google will therefore retain the old, non-existing URL in its index, crawl it over and over again, and keep following the redirect. Given that Google assigns every website a crawling budget, limiting the number of URLs the Googlebot can crawl, the prevalence of 302 and 303 redirects can result in this budget being wasted on defunct URLs.
If you don’t want to use the old URL any more, redirect it using normal 301 redirects. Soon after, the old URL will disappear from the index and will no longer be crawled. If you are using temporary redirects, check back regularly to make sure they are being sued for their correct purpose, or whether they would be better off being set to 301 redirects. Once the original URL becomes active again, the redirect can be removed altogether.
3. URLs with duplicate content
Duplicate content (DC) refers to identical content which is found under at least two different URLs. This can be harmful for your ranking. How should Google know which of the two URLs is the “right” one and should therefore be ranked higher in search results? After all, both contain exactly the same content. Google often ends up chopping and changing between the two URLs, resulting in neither attaining a particularly high ranking. Duplicate content errors must be addressed at all costs.
One common cause of duplicate content are websites which are accessible both with and without the www prefix, and where no redirect is in place. Technically speaking, the www version is a separate subdomain. When setting up your domain, you should decide which variant is to be stored in Google’s index – it doesn’t really matter which. Redirect the undesired variant to your preferred URL using a 301 redirect. Problem solved.
Similar problems can occur with HTTPS/HTTP and URLs accessible with a slash at the end or without.
Of course, it could also be the case that you actually do have duplicated content on your website. This often happens with article descriptions in online shops. Say, for example, you are selling pullovers. Same brand, same style but different colours and sizes. The product descriptions are likely to be identical, and this counts as duplicate content. Ideally, each article page would have a unique description, but this can evidently be time consuming for larger shops. Generally, shop owners optimise their sites at the category level rather than by the products themselves. The products can sometimes go out of stock or be taken off sale, meaning a carefully optimised product page URL then disappears.
4. URLs with duplicate titles and URLs with missing titles
Title tags ought to play a significant role in your web projects because they have a direct effect on rankings and are taken into account by Google when determining the relevance of a website. Google also displays the content of title tags as headings on its SERPs. Google users can see these headings and decide whether or not to click on your website based on its heading. Click rate is another important ranking factor for Google.
What makes a good title?
- Main keyword right at the start
- Title contains a call-to-action to the user
- Not too long – space is limited. When a title is too long, Google cuts off the end and replaces it with dots. Length is measured not in characters but in pixels. You should be safe with approximately 58 characters. Otherwise there are various snippet tools to help display your title correctly.
- Title encourages users to click.
The important thing is that each sub-page has its own title. In this sense, duplicate titles pose a similar threat to duplicate content, and should be avoided. URLs which have no title are missing out on potential for optimisation, so make sure that every page has a meta title tag.
5. “URL not found in sitemap” and sitemaps with URLs which couldn’t be found
A sitemap is a XML file which contains a list of all URLs on a website. It is effectively a website table of contents for benefit of search engines.
Google themselves provide a simple explanation of the purpose of sitemaps on their own support pages – check out this article.
During an onpage crawl, XOVI crawls a website to its set depth and follows all internal links, identifying every link and comparing it to the sitemap. Sometimes, URLs are found which are not visible in the sitemap, meaning that the sitemap is incomplete and should be updated in order to contain all URLs.
The opposite can also occur. Imagine you have removed a page from the website, perhaps because your online shop no longer has a certain product in stock. The URL still remains in the sitemap however and is therefore unnecessarily crawled by Google, wasting the crawl budget for the site. The sitemap can often be set to update automatically in the shop system or CMS. Plugins also exist for these systems.